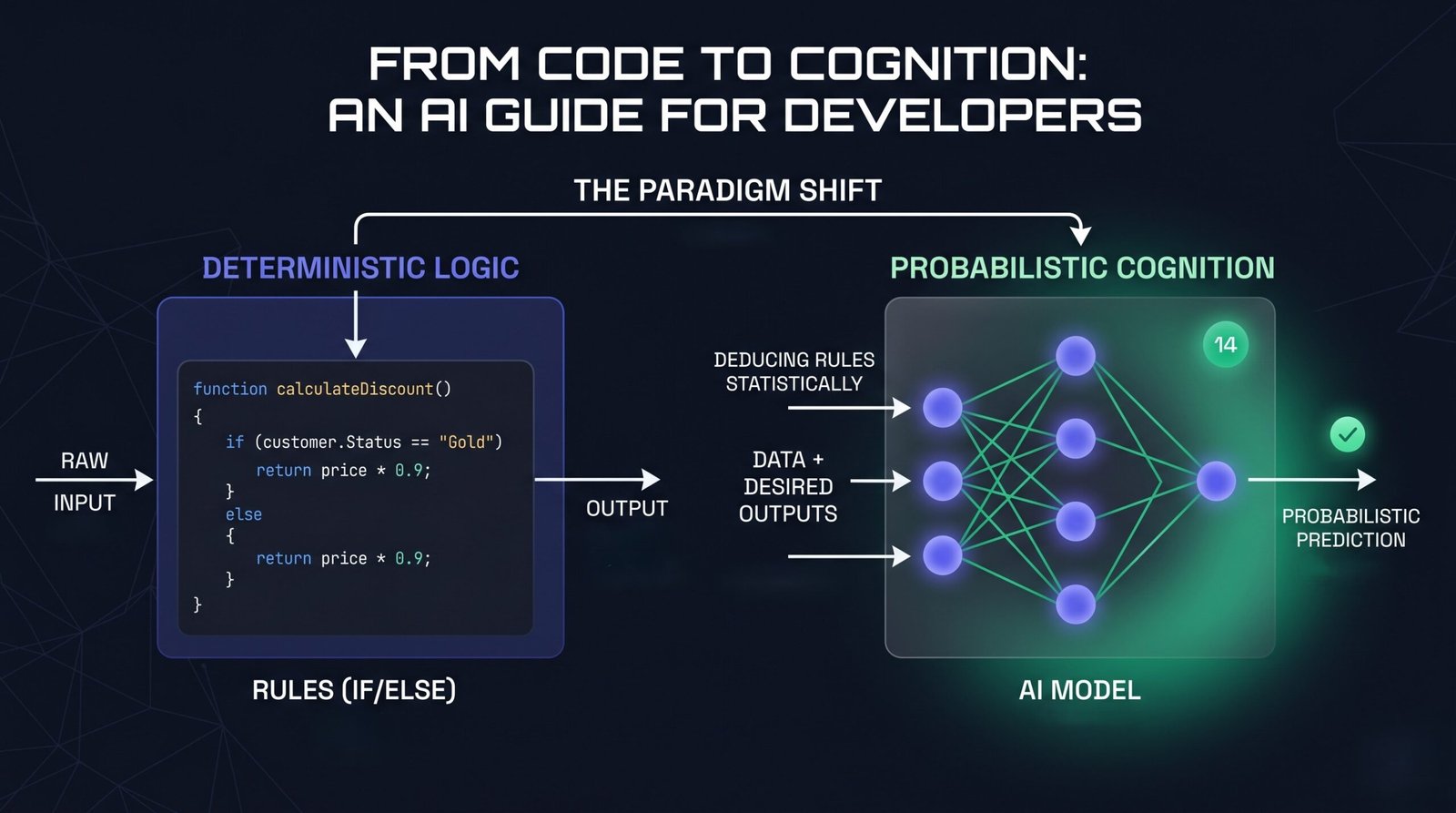
As software engineers, we are accustomed to building systems based on determinism—where an input X always produces a predictable output Z. When we start working with Large Language Models (LLMs), however, many of us fall into the trap of treating them either like a traditional, deterministic database or a truly autonomous mind. Both assumptions are wrong.
To build reliable, production-grade AI features, we must adopt the correct mental model: An LLM is a stateless, highly sophisticated probabilistic text-completion engine.
By understanding how these models handle text, manage memory constraints, and select words, we can move from trial-and-error “prompt engineering” to repeatable, predictable system design.
The Core Mental Model: Text Completion and Statelessness
To effectively integrate LLMs into software architecture, we must first strip away the high-level abstractions of “chatbots” and “assistants.” At their functional core, these models operate on two fundamental principles: autoregressive generation and API statelessness. Mastering these concepts is essential for transitioning from naive implementation to robust, production-ready engineering.
The Core Token Loop
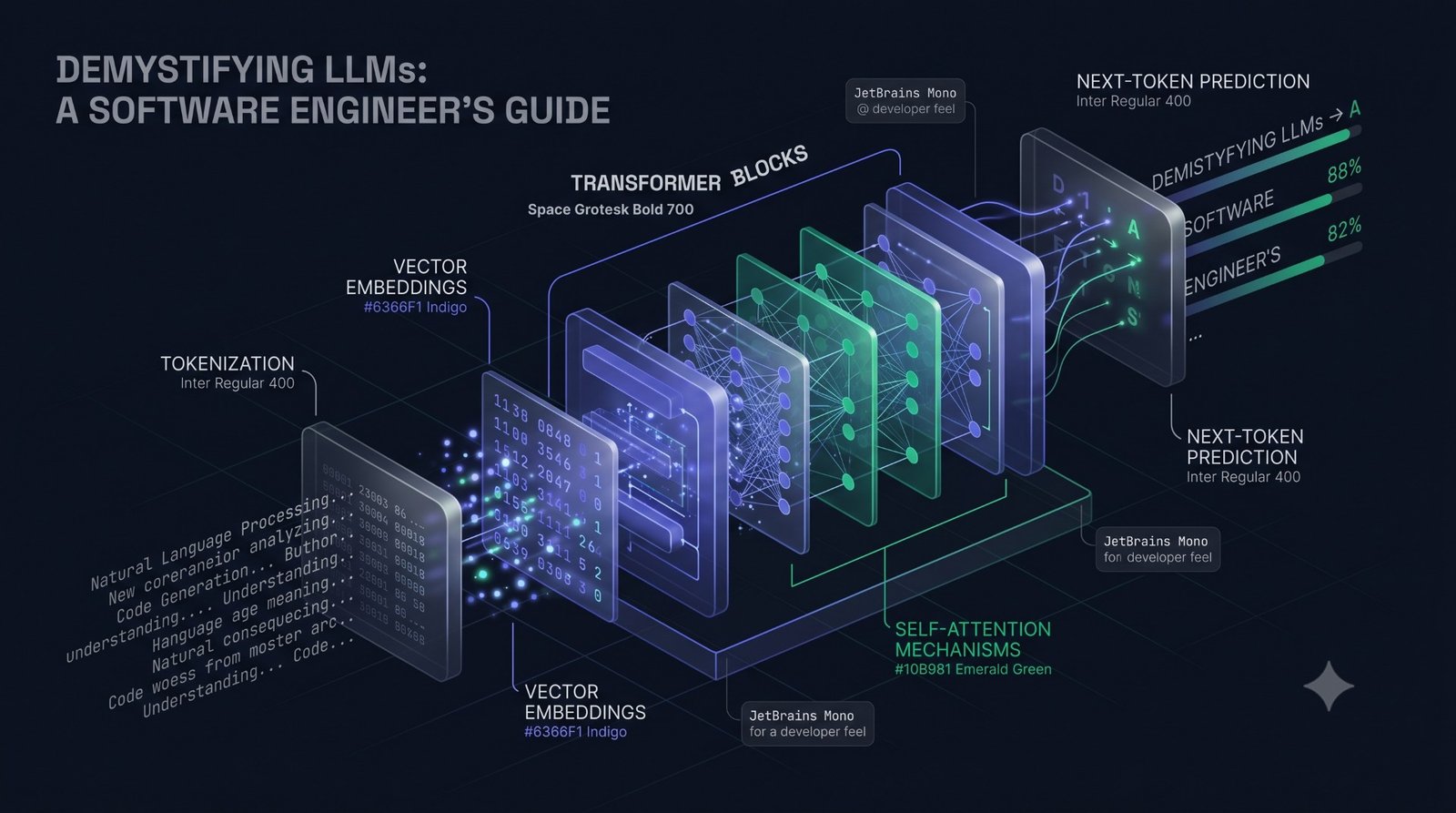
When you strip away the conversational interfaces, an LLM is reduced to a single operation: autoregressive text completion.
The model doesn’t “think” or look up facts in a database. It performs a simple, continuous loop:
- It takes your input text (the prompt).
- It uses its neural network to calculate a probability score for every potential next word or word fragment (token) in its vocabulary.
- It selects the most statistically likely next token.
- It appends that new token to the prompt.
- It feeds the entire, newly expanded text back into itself to predict the subsequent token.
Performance Tip: The “Memory Shortcut” (KV Caching)
You might notice that the process described above implies we re-process the entire prompt for every single new token, which sounds computationally expensive. In practice, modern LLM systems use a technique called KV Caching. Instead of re-calculating everything from scratch, the system “caches” or saves the intermediate states of previous tokens. This allows the model to efficiently build on what it has already generated without needing to re-process the entire history from scratch, significantly speeding up the generation process.
This sequential, token-by-token prediction continues until the model hits a predefined output limit or generates a special End-of-Sequence (EOS) token. Every piece of content—from a single paragraph to a structured JSON object—is built through this continuous statistical inference process.
Token: The fundamental unit of text an LLM processes. A token is rarely a single character or a complete word; it is usually a sub-word unit or common punctuation. (In English, roughly 4 characters or 0.75 words equals 1 token.)
The Statelessness Trap
A common source of architectural bugs is assuming the LLM API remembers context between requests.
LLM APIs are fundamentally stateless. Every API call is completely isolated. The model does not retain memory of the log file you sent five seconds ago or the question you asked before that.
To create the illusion of a continuous conversation (or state), your application layer must take on the full responsibility for memory management.
You must explicitly compile the entire conversation history—including the system instructions, all user prompts, and all prior model responses—into a single, structured payload and send it back to the model with every API invocation. As the conversation grows, this historical payload consumes more memory and computational resources, driving up both latency and cost.
Managing Conversational State in Code
The following Python example demonstrates how a simple application class must manually handle the state array (self.history) because the LLM itself remains stateless.
import os
from typing import List, Dict
from openai import OpenAI
class ConversationalSessionManager:
def __init__(self, system_instruction: str):
# Initializes the stateful memory array on the application side.
# The LLM API itself remains completely stateless.
self.client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
self.model = "gpt-4o"
self.history: List[Dict[str, str]] = [
{"role": "system", "content": system_instruction}
]
def send_message(self, user_message: str) -> str:
# 1. Append the current user state to the history array
self.history.append({"role": "user", "content": user_message})
try:
# 2. Execute a completely stateless request containing the entire historical context
response = self.client.chat.completions.create(
model=self.model,
messages=self.history,
temperature=0.0 # Enforce predictable output
)
# 3. Extract the predicted text completion
model_response = response.choices[0].message.content
# 4. Mutate local state to include the model's response for the next loop
self.history.append({"role": "assistant", "content": model_response})
return model_response
except Exception as e:
# Roll back the history to prevent state corruption on failure
self.history.pop()
raise RuntimeError(f"Stateless invocation failed: {str(e)}")
# Example Execution:
if __name__ == "__main__":
system_prompt = "You are an automated log parsing assistant. Respond only with structured analysis."
session = ConversationalSessionManager(system_instruction=system_prompt)
# Request 1: Providing the raw contextual data
res1 = session.send_message("Log entry: 2026-06-02 10:14:22 ERROR: DbConnection timeout.")
# Request 2: Dependency on previous context, which is sent back implicitly by the class.
res2 = session.send_message("What infrastructure component caused that exception?")By manually managing state, you gain explicit control to optimize payload size, trim old context, and predictably control cost.
Understanding Tokens: The True Currency of LLMs
To an LLM, your code or natural language text is illegible. The model processes text only after it is translated into a sequence of tokens (integer IDs). Understanding token behavior is essential, as it dictates your API cost, application speed, and structural limits.
What is a Token?
Before raw text reaches the neural network, it passes through a deterministic pre-processor called a tokenizer. Modern models use a technique called Byte-Pair Encoding (BPE). BPE works by analyzing massive amounts of training data and grouping the most common pairs of characters or bytes into a single, efficient token. This is why a single token often represents a variable-length chunk of text, like a sub-word. The tokenizer then maps each unique sub-word token to a discrete integer ID. The LLM performs all its complex math purely on these arrays of integers.
The “Developer Tax”: Hidden Cost and Performance Penalties
While standard English prose is tokenized efficiently, structural and technical data often is not. This leads to a hidden penalty known as the Developer Tax:
- Structural Code & JSON Overhead: Tokenizers, trained on natural language, struggle with syntax like indentation, quotation marks, and consecutive spaces. A single indented line of JSON can cost three to four times the token budget of the same line written as flat text.
- The Non-English Penalty: Because BPE relies on the character frequencies of its training data, non-English languages are often broken down into many more, smaller fragments. A phrase that takes 3 tokens in English might expand to 15 tokens when translated into Japanese or German, significantly increasing cost and cutting down the usable context window.
Context Windows: The Engineering Equivalent of RAM
The context window is often marketed as the maximum length of a document a model can read. For an engineer, it is best viewed as the maximum static RAM allocation available for a single, isolated execution.
This window defines the hard ceiling for the combined size of the input prompt and the output response. Exceeding this limit by even one token will cause the API call to fail or the output to be abruptly cut off.
Crucially, the time it takes the model to process the input scales poorly—it has an algorithmic complexity of O(N²) relative to the input length N. This means that if you double the length of your prompt, the computational time needed to process it quadruples. This is why managing token efficiency is a vital strategy for preventing latency degradation.
Production Tip: Benchmarking Token Footprints
To mitigate the Developer Tax, ensure you compile structural data like JSON into a minified format (no extra spaces, no indentation) before sending it to the model. This ensures your budget is spent on meaningful context, not wasted on structural whitespace.
Controlling the Output: Demystifying Hyperparameters
In traditional software, control flow is managed by conditionals and loops. In generative AI, you control the output behavior using hyperparameters, which are settings that change the mathematical rules for how the engine selects the next token.
The Probability Pool (Logits) and the Softmax Step
When the LLM is about to generate the next token, it first assigns a raw numerical score, called a logit, to every possible word or sub-word in its vocabulary.
To make these raw scores usable, the model applies the Softmax function. This mathematical step converts all the raw scores (logits) into a clear probability distribution, ensuring all possibilities add up to 100%. This result is the ‘probability pool’ where every token has a precise chance of being selected.
If the system simply chose the highest-probability token every time (a technique called greedy decoding), the output would be repetitive and robotic. To avoid this, developers adjust two primary controls: Temperature and Top-P.
Temperature: The Creativity Dial
Temperature (T) is a setting that controls how much randomness and variety the model uses when selecting the next word.
- Temperature = 0.0 (Strictly Predictable): The most conservative setting. The model always selects the single most likely token. This ensures strict consistency—the same prompt always gives the same answer. Use this for strict tasks like code generation, data extraction, and schema compliance.
- Temperature = 1.0 (Balanced Output): The default setting. The model mostly chooses likely words but allows for some statistical variety to make the language feel natural and less robotic. Use this for general conversation and writing.
- High Temperature (T > 1.0) (High-Risk Creative Output): This makes the model highly adventurous, choosing statistically unlikely words. While great for brainstorming, it dramatically increases the risk of the model making up facts (hallucination), losing context, or producing nonsensical sentences.
Top-P (Nucleus Sampling): Cutting Off the Nonsense
While Temperature affects the spread of probabilities across all words, Top-P (or Nucleus Sampling) controls the size of the pool of words the model can choose from. It dynamically removes the words that are least likely to be relevant.
How it works: Top-P ranks all available words by probability and then includes only the most probable words that collectively add up to your specified percentage (the ‘P’ value).
Example: If you set Top-P to 0.90, the model creates a boundary that includes only the most probable words that make up 90% of the total likelihood. The remaining 10% of the vocabulary—the low-probability “tail”—is completely eliminated. This is a safety mechanism to ensure that even if the model is confused, it cannot pick a random, irrelevant word.
Engineering Protocol: Because Temperature and Top-P both affect randomness, treat them as mutually exclusive controls. When tuning, set one to a neutral value (T=1.0 or Top-P=1.0) before adjusting the other.
| Production Use-Case | Target Temperature | Target Top-P | Execution Profile |
| SQL Query Generation & Schema Mapping | 0.0 | 1.0 (Locked) | Strict determinism; eliminates syntax variations. |
| JSON Extraction / Log Parsing | 0.0 | 1.0 (Locked) | Maximize compliance with strict data schemas. |
| RAG Summarization & Factual Q&A | 0.2 to 0.3 | 0.95 | Highly focused; minimizes the risk of factual fabrication. |
| Customer Support Chat Routing | 0.5 to 0.7 | 0.90 | Balanced conversational flow with bounded vocabulary risks. |
| Creative Copywriting & Brainstorming | 1.0 to 1.2 | 0.85 | High entropy; introduces unexpected associations while cutting off nonsense. |
Performance Metrics: Managing Latency and UX
Unlike traditional APIs where a response time over 500ms is a bottleneck, LLM responses often take several seconds. To prevent user frustration and high churn rates, you must break down latency into its two distinct computational phases.
Understanding Latency: Pre-fill vs. Decoding
When you send a prompt, the LLM processes it in two phases:
- The Pre-fill Phase (Reading Your Prompt): In this first step, the model reads and processes all of your input text (instructions, context, and history) at once. Because the system knows every word upfront, the hardware (GPU) can process the entire block of text in parallel. This phase is highly efficient, though it slows down quadratically with longer prompts.
- The Decoding Phase (Writing the Response): Once the input is processed, the model starts writing the output. This must happen sequentially, one token at a time, because the model needs the previously generated token to predict the next one. This sequential bottleneck is almost always the slowest part of using an LLM.
Streaming vs. Non-Streaming: Breaking the Blocking Pattern
If you use the standard non-streaming REST pattern (where the client waits for the full payload before the server responds), your application will freeze. For example, if a 500-token summary takes 10 seconds to generate, your user will stare at a blank loading spinner for 10 seconds, leading to a poor user experience and potential HTTP 504 gateway timeouts.
To build production-grade interfaces, you must transition to a streaming architecture. By configuring the API to stream, the LLM engine yields tokens to your application the exact millisecond they are generated in the decoding phase.
Time-to-First-Token (TTFT) and Server-Sent Events (SSE)
The gold-standard performance metric is Time-to-First-Token (TTFT). TTFT measures the duration between the request being sent and the application rendering the very first piece of generated text.
While the total response might still take 10 seconds, a streaming connection can often bring the TTFT down to under 200 milliseconds. This immediate visual feedback completely changes the user’s perception of performance.
The industry-standard protocol for delivering these token streams to web browsers is Server-Sent Events (SSE). SSE is a lightweight, unidirectional push over standard HTTP, making it simpler to implement than WebSockets.
Production Architecture Note: If you route streamed tokens through a backend (like a reverse proxy), you must ensure that all downstream proxy components have response buffering disabled. If the proxy tries to buffer the response (e.g., to gzip it), your stream will choke, and you will revert back to a blocking, high-latency request.
Building for Production: Best Practices for Clean Code
Moving an LLM implementation from a prototype to production requires a shift from exploration to defensive systems design. Unhandled edge cases can lead to thread exhaustion, cascading API failures, and unexpected cloud costs.
Deterministic Structures: Ditching the Unreliable Regex Method
Early on, developers often asked models for structured data (like JSON) using a simple text prompt, and then used Regular Expressions (Regex) or simple string parsing to extract the data.
This approach is highly unstable. Because LLMs are probabilistic, their output is never guaranteed to be perfect. A slight change—an added conversational phrase before the JSON, a missing bracket, or a variation in structure—will cause your Regex to fail and break your application at runtime.
To ensure your application can reliably process LLM output, you must use features like Structured Outputs with strict schema enforcement (e.g., specifying a Pydantic or Zod schema).
When you provide the API with a precise data blueprint, the model’s behavior is fundamentally changed. The engine uses your schema to mathematically limit the tokens it can choose. For instance, if your schema requires an integer, the model is physically prevented from outputting any non-numeric tokens. This guarantees the output perfectly matches your code’s expected data structure, eliminating parsing failures.
The Production Checklist
Before deploying any AI-assisted layer, your system architecture must address four core operational risks:
| Operational Risk | Production-Grade Mitigation Strategy | Concrete Implementation Pattern |
| Unbounded Latency / Hanging Threads | Hard Execution Timeouts & Circuit Breakers | Set strict connection and read timeouts on your HTTP client (e.g., max 15s). Implement circuit breakers (like those found in libraries such as Resilience4j) to “fail fast” if the AI provider experiences unexpected latency spikes. |
| API Throttling / Rate Limits (HTTP 429) | Exponential Backoff with Random Jitter | Never retry failed calls immediately. Use an asynchronous retry queue that doubles the wait interval between attempts (2x seconds) and adds a randomized offset (jitter). This prevents thousands of worker threads from retrying simultaneously, which can cause a self-inflicted Distributed Denial of Service (DDoS) state. |
| Token Cost & Memory Blowout | Hard Ceiling Constraints & Client-Side Truncation | Always specify a max_tokens limit on every outgoing payload to prevent runaway generation bills. Prior to dispatch, use a library (like tiktoken) to programmatically prune or truncate old context arrays once they cross a designated safety threshold. |
| Single-Point-of-Failure / Provider Outage | Gateway Abstraction Layer | Avoid hardcoding specific provider client libraries in your core logic. Build or utilize an internal gateway interface. If your primary provider fails, your routing engine can dynamically fall back to an alternate model or cloud region without needing a code deployment. |
Clean code in AI engineering is not about writing clever prompts; it is about surrounding probabilistic engines with resilient, predictable infrastructure using standard distributed systems patterns.