As software developers, we are used to being the ultimate source of logic in our applications. We write the code, define the database schemas, and establish the API contracts. But recently, a new paradigm has taken over the industry: Artificial Intelligence.
If you feel overwhelmed by the sudden influx of math, statistics, and foreign terminology, you are not alone. This guide is designed to help you transition from traditional programming to AI, leveraging your existing software development mindset.
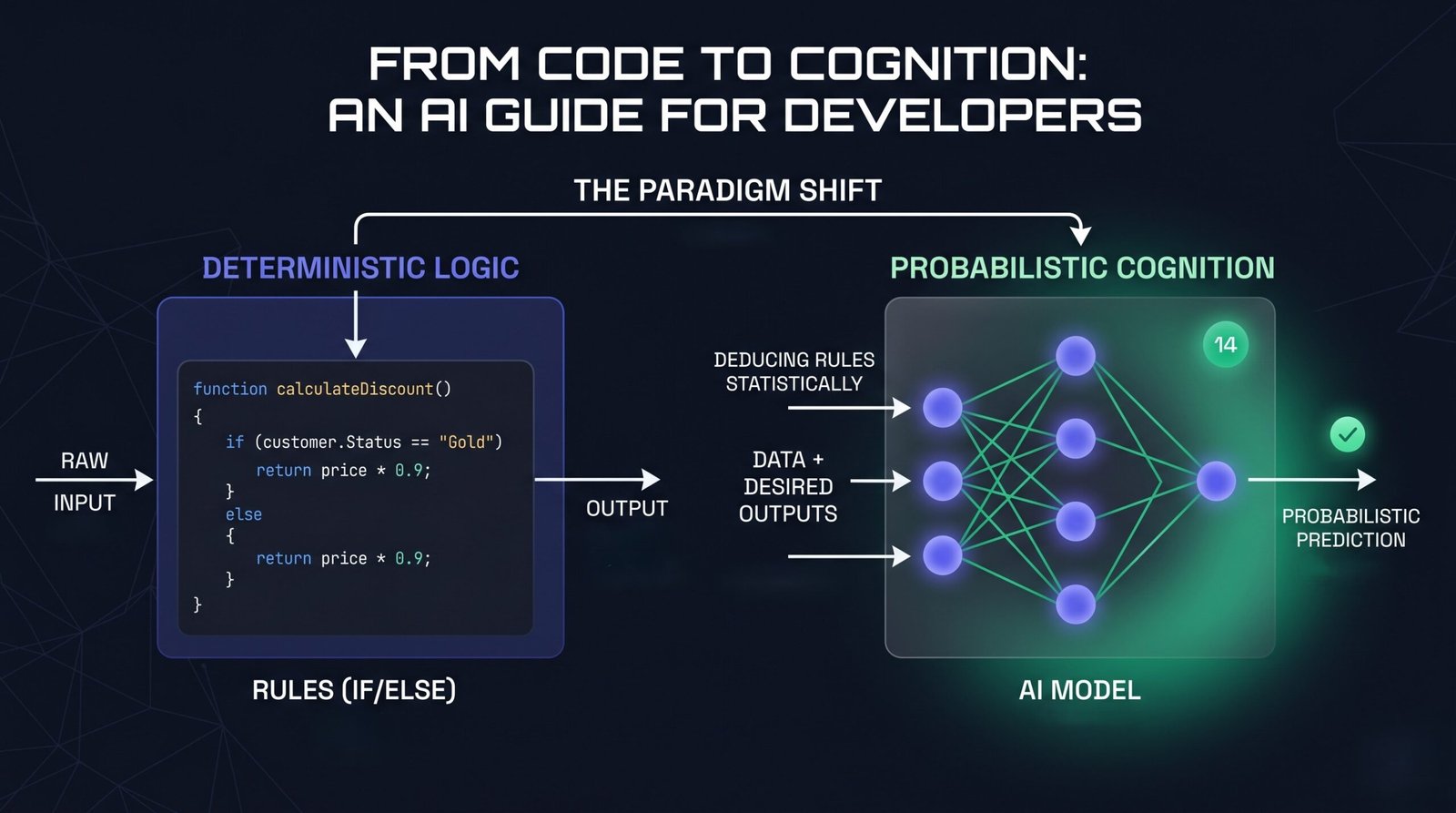
Shifting the Paradigm: From If/Else to Probabilities
For decades, software engineering has been deterministic. We write explicit Rules (code), feed in Data (inputs), and get a predictable Output. If a bug occurs, we trace the stack trace or step through a debugger to find the broken line of logic.
Traditional Programming: Data + Rules ➔ Output
Artificial Intelligence – specifically Machine Learning (ML) – flips this script entirely. Instead of coding the rules, we provide the system with Data and the desired Outputs. The AI algorithm uses these examples to statistically deduce the underlying Rules.
Machine Learning: Data + Outputs ➔ Rules
Once the system deduces these rules, it packages them into what we call a Model. You can think of a model as a compiled, black-box function that you can pass new data into to get a prediction.
Why Developers are Uniquely Positioned for AI
There is a common misconception that to work with AI, you need a PhD in mathematics or statistics. While that is true for the researchers designing new architectures, it is not true for the software engineers building applications with them.
In fact, software developers are uniquely positioned to thrive in the AI era for several reasons:
- AI Needs an Ecosystem: A machine learning model is completely useless in isolation. It needs an API wrapper, a user interface, a database to store states, authentication, and secure cloud hosting. You already know how to build all of this.
- Data is Just State: Training or using an AI model requires data pipelines—ingesting, cleaning, transforming, and storing data. This is fundamentally a backend engineering and system design problem that developers solve every day.
- The Debugging Mindset: Interacting with AI (especially Large Language Models) is highly iterative. Prompt engineering, fine-tuning, and evaluating model outputs require the exact same logical, hypothesis-driven debugging process you use to fix a broken production build.
- Integration is the New Creation: Today, the most powerful AI capabilities are accessed via simple REST APIs or SDKs. If you know how to make an HTTP request and handle JSON payloads, you can build state-of-the-art AI features into your apps in minutes.
Demystifying the Core Concepts: AI vs. ML vs. DL
To navigate this landscape, it is helpful to think of AI, ML, and DL as nested namespaces.
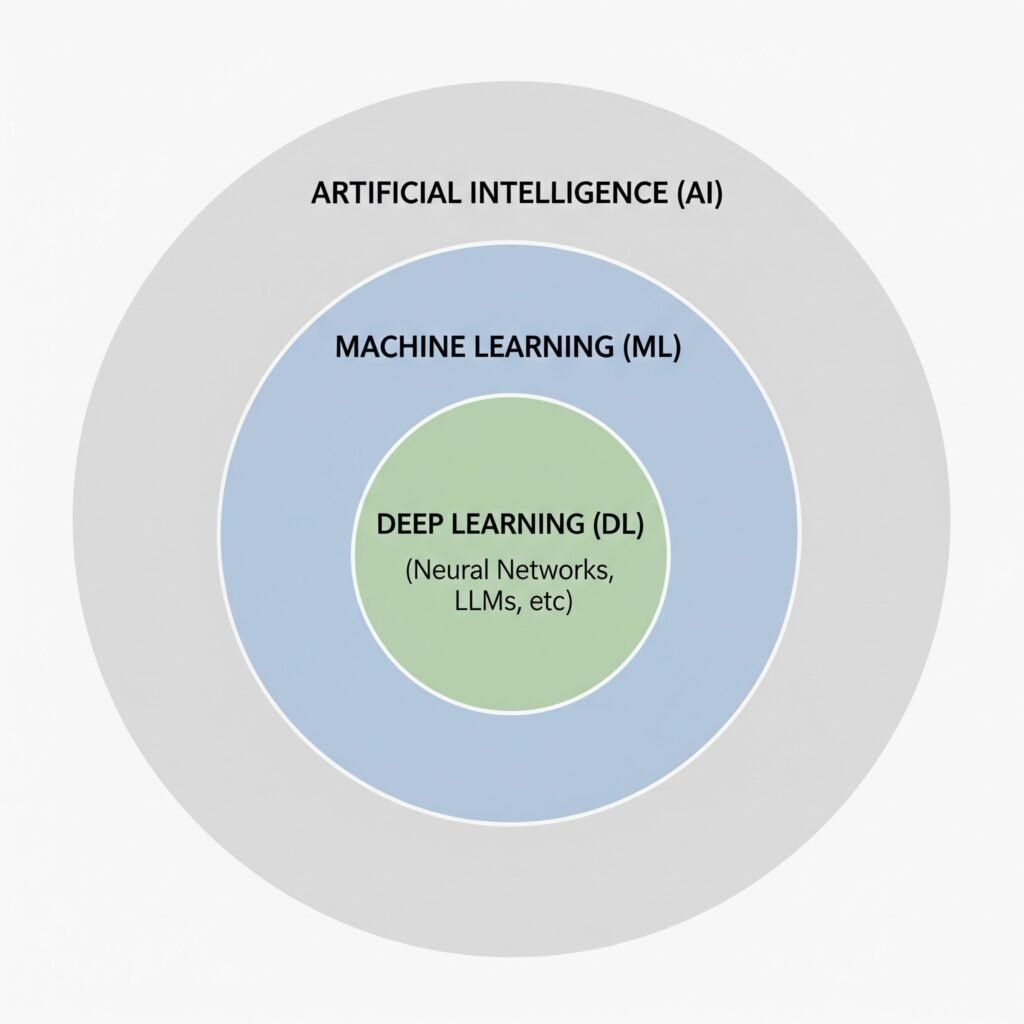
Artificial Intelligence (AI): The Global Namespace
AI is the broadest umbrella. It refers to any system or technique that enables computers to mimic human intelligence or behavior. This includes things that aren’t modern “AI” at all—such as a complex, hardcoded if/else rules engine, or the classic pathfinding algorithms (like $A^*$) used in video games. If a machine mimics decision-making, it falls under AI.
Machine Learning (ML): The Sub-Namespace
ML is a specific subset of AI where the system learns patterns from data instead of relying on manually written rules.
- The Developer Metaphor: Think of ML as writing code that can dynamically adjust its own configuration files based on the traffic it receives.
- Limitations: Traditional ML algorithms work incredibly well on structured data (tabular data like CSVs). However, they require manual “feature engineering.” If you want an ML model to recognize fraudulent transactions, a developer must explicitly define and format the data inputs (e.g., transaction frequency, geographic distance).
Deep Learning (DL): The Private Inner Class
Deep Learning is a highly specialized subset of ML. It relies on Artificial Neural Networks—layers of mathematical functions styled roughly after the neurons in the human brain.
- The Unstructured Data Breakthrough: Unlike traditional ML, Deep Learning does not need manual feature engineering. You can feed it raw, unstructured data—such as raw pixels of an image, audio recordings, or vast text files.
- Modern Relevance: Almost every major AI breakthrough in the last decade—including Large Language Models (LLMs)—is a product of Deep Learning.
The Modern AI Developer Stack: Prompting, RAG, and Fine-Tuning
As an application developer, you do not need to compile neural networks or train base models from scratch. Instead, your job is to take incredibly powerful, pre-trained Foundation Models (like Gemini or GPT) and integrate them into your software products.
There are three primary architectural patterns developers use to build AI products, ranging from easiest (and cheapest) to most complex:
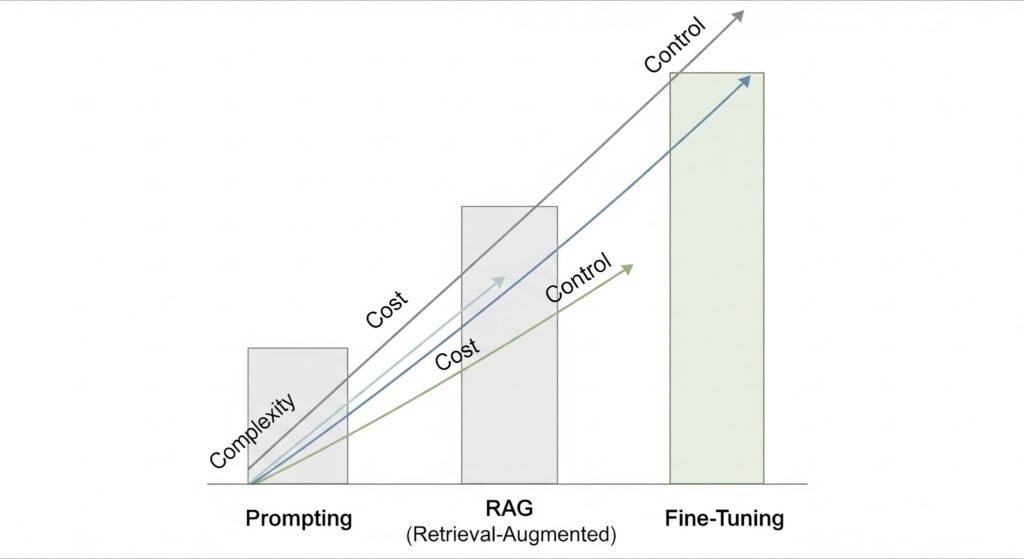
Prompt Engineering (The Application Layer)
This is where every developer starts. You use the model out of the box and pass instructions and context directly in the API request (known as the “context window”).
- How it works: You write a clean system prompt defining the persona, task, and formatting rules.
- Developer Metaphor: Think of this as passing parameters to a highly flexible, open-ended function.
- Best for: Sentiment analysis, translating formats (e.g., HTML to JSON), drafting emails, or simple Q&A.
Retrieval-Augmented Generation (RAG) (The Database Layer)
An LLM only knows what it was trained on. It doesn’t know about your user’s private data, database entries, or local API documentation. RAG solves this without changing the model itself.
- How it works:
- 1. A user asks a question.
- 2. Your backend searches your traditional database or a specialized Vector Database (which stores data based on semantic meaning, not just exact keywords) for matching records.
- 3. Your backend pulls the relevant records, injects them into the LLM prompt as context, and says: “Answer the user’s question using ONLY this retrieved data.”
- Developer Metaphor: This is like giving an open-book exam to a genius. The genius (LLM) didn’t memorize your textbook, but you are handing them the exact pages they need to answer the question.
- Best for: Building customer support chatbots that query company FAQs, searching through private codebase repositories, or analyzing user-specific PDF documents.
Fine-Tuning (The Customization Layer)
Fine-tuning involves taking a pre-trained foundation model and training it further on a specific, narrow dataset to change its core behavior, tone, or style.
- How it works: You feed the model thousands of input-output pairs showing exactly how you want it to behave. This permanently changes some of the model’s internal weights.
- Developer Metaphor: Think of this as writing a custom subclass. You inherit all the capabilities of the base class (the foundation model) but override specific methods to conform to highly unique behaviors.
- Best for: Teaching a model a highly specific programming syntax, enforcing a strict brand voice, or optimizing performance for tiny, edge-device models.
The Practical Integration Layer: APIs and LLMs
As a software engineer, you interact with Large Language Models (LLMs) in two distinct ways:
- As a Consumer: Using AI-powered extensions to write, refactor, and debug your application.
- As a Builder: Integrating AI directly into your applications to solve complex business logic.
These two modes are closely connected. The mental habits you build while consuming AI are exactly the skills you need to build with it.
Consuming AI: The Prompt Engineering Mindset
Let’s say you are writing a C# .NET API. You encounter an unexpected NullReferenceException in a complex LINQ query. You open GitHub Copilot, highlight the code block, and prompt it to find and fix the bug.
To get a perfect fix from Copilot, you don’t just ask: “Fix this.” Instead, your brain automatically applies structured context:
- The Goal: “Find and resolve the null reference exception in this query.”
- The Context: You supply the exact method body and the database entity classes.
- The Constraints: “Keep the database model unchanged, preserve our dependency injection pattern, and write a xUnit test covering the fix.”
- The Expected Output: “Provide the corrected method and explain what caused the issue.”
This structured feedback loop is Prompt Engineering. You are wrapping unstructured intent in explicit, deterministic boundaries.
Building AI: Bringing LLMs into Your Own Code
Once you understand how to prompt a tool like Copilot, you are ready to use those exact same principles to build AI capabilities inside your own applications.
You do not need to build, train, or even host a neural network to make your software “intelligent.” Instead, you call LLM APIs (like Gemini, OpenAI, or Claude) directly from your code. In the .NET ecosystem, you can do this using standard HTTP requests, SDKs, or official orchestration libraries like Semantic Kernel or Microsoft.Extensions.AI.
Here is an example of an ASP.NET Core API controller using a direct HttpClient request. It acts as an intelligent support agent, taking incoming, unstructured email text and classifying its sentiment and priority without a single hardcoded line of text parsing:
using System.Net.Http.Json;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/support")]
public class SupportAgentController : ControllerBase
{
private readonly HttpClient _httpClient;
private const string ApiKey = "YOUR_GEMINI_API_KEY";
public SupportAgentController(HttpClient httpClient)
{
_httpClient = httpClient;
}
[HttpPost("classify")]
public async Task<IActionResult> ClassifyTicket([FromBody] TicketRequest request)
{
// 1. Establish the System Prompt (The Rules)
string systemInstruction = "You are a professional support ticket triager. " +
"Analyze the ticket and return a JSON object with: " +
"1. 'sentiment' (Positive, Neutral, Negative) " +
"2. 'priority' (High, Medium, Low) " +
"3. 'suggestedAction' (string) " +
"Respond ONLY with the raw JSON string.";
// 2. Prepare the payload (System prompt + User's Data)
var payload = new
{
contents = new[] {
new {
parts = new[] {
new { text = $"{systemInstruction}\n\nTicket Text: {request.EmailContent}" }
}
}
}
};
// 3. Make the API Call to the Foundation Model
var response = await _httpClient.PostAsJsonAsync(
$"[https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-preview-09-2025:generateContent?key=](https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash-preview-09-2025:generateContent?key=){ApiKey}",
payload
);
if (!response.IsSuccessStatusCode)
return StatusCode(500, "AI Service Unavailable");
var result = await response.Content.ReadFromJsonAsync<GeminiResponse>();
string aiJsonResult = result?.Candidates?[0]?.Content?.Parts?[0]?.Text ?? "{}";
// 4. Return the structured classification back to your deterministic system
return Ok(aiJsonResult);
}
}
public record TicketRequest(string EmailContent);
public record GeminiResponse(Candidate[] Candidates);
public record Candidate(Content Content);
public record Content(Part[] Parts);
public record Part(string Text);By hitting this endpoint, your traditional, deterministic C# code suddenly gains the ability to “understand” and structure natural language text. From here, you can feed that structured JSON directly into your traditional SQL databases or messaging queues.
Conclusion: Embracing the Role of the AI Engineer
The rise of AI does not mean the end of software developers. Rather, it represents evolution.
In the past, we were limited to writing instructions that could only process perfect, structured data. If a user made a typo or sent an unstructured email, our code crashed or returned unreadable errors. Today, we can use LLM APIs as probabilistic adapters on top of our deterministic infrastructure.
You don’t need a PhD to get started. You already have the most valuable skills in the AI ecosystem:
- You know how to build secure, scalable backends.
- You know how to format, sanitize, and validate API inputs and outputs.
- You already debug using the exact same logical, step-by-step approach used in prompt engineering.
Think of AI not as a threat, but as a new set of highly flexible APIs in your backend toolkit. Start small, experiment in your IDE with Copilot or any AI extension of your choice like Claude or Gemini, write your first system prompt, and begin bridging the gap from deterministic code to cognitive applications.
Leave a Reply